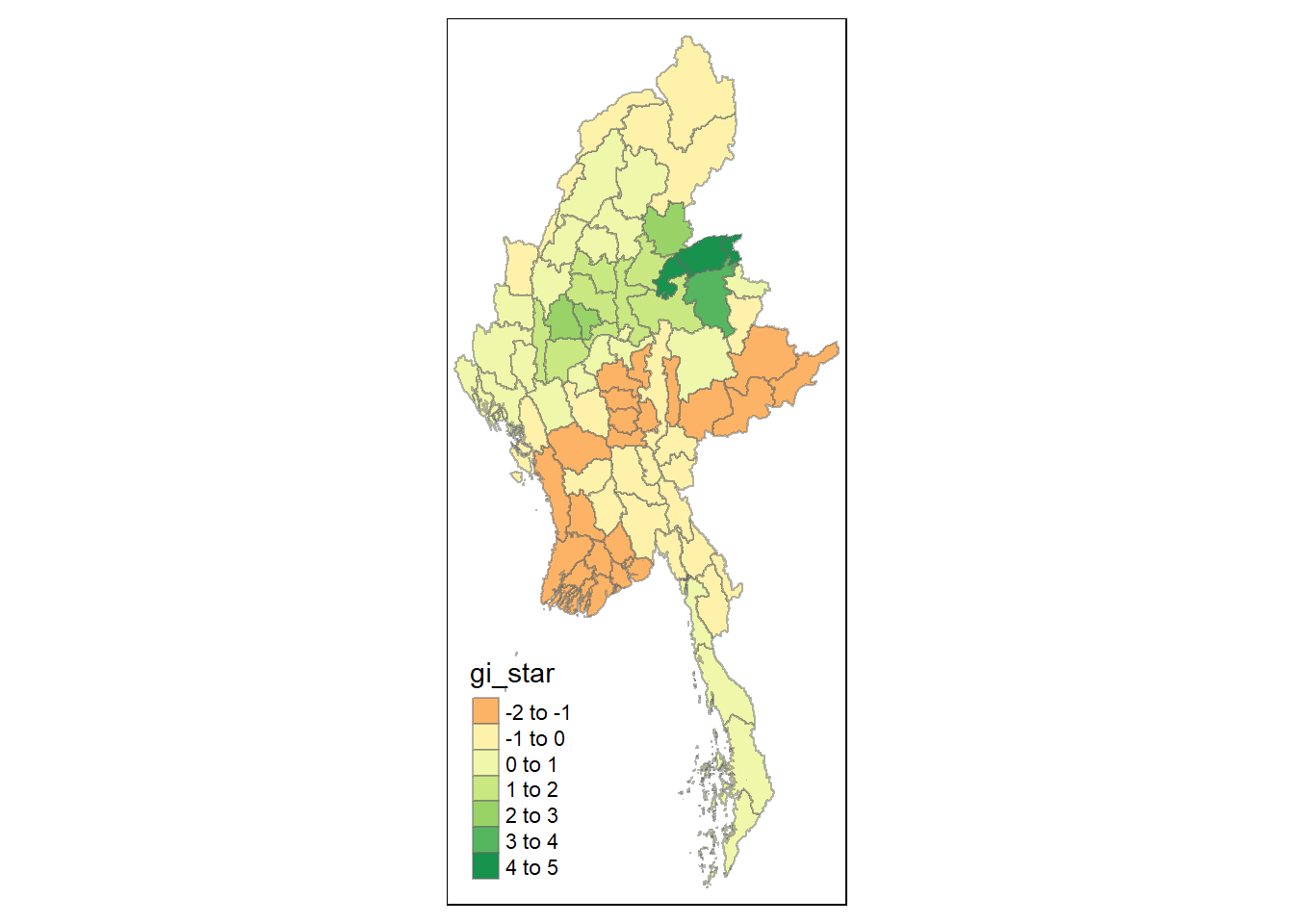
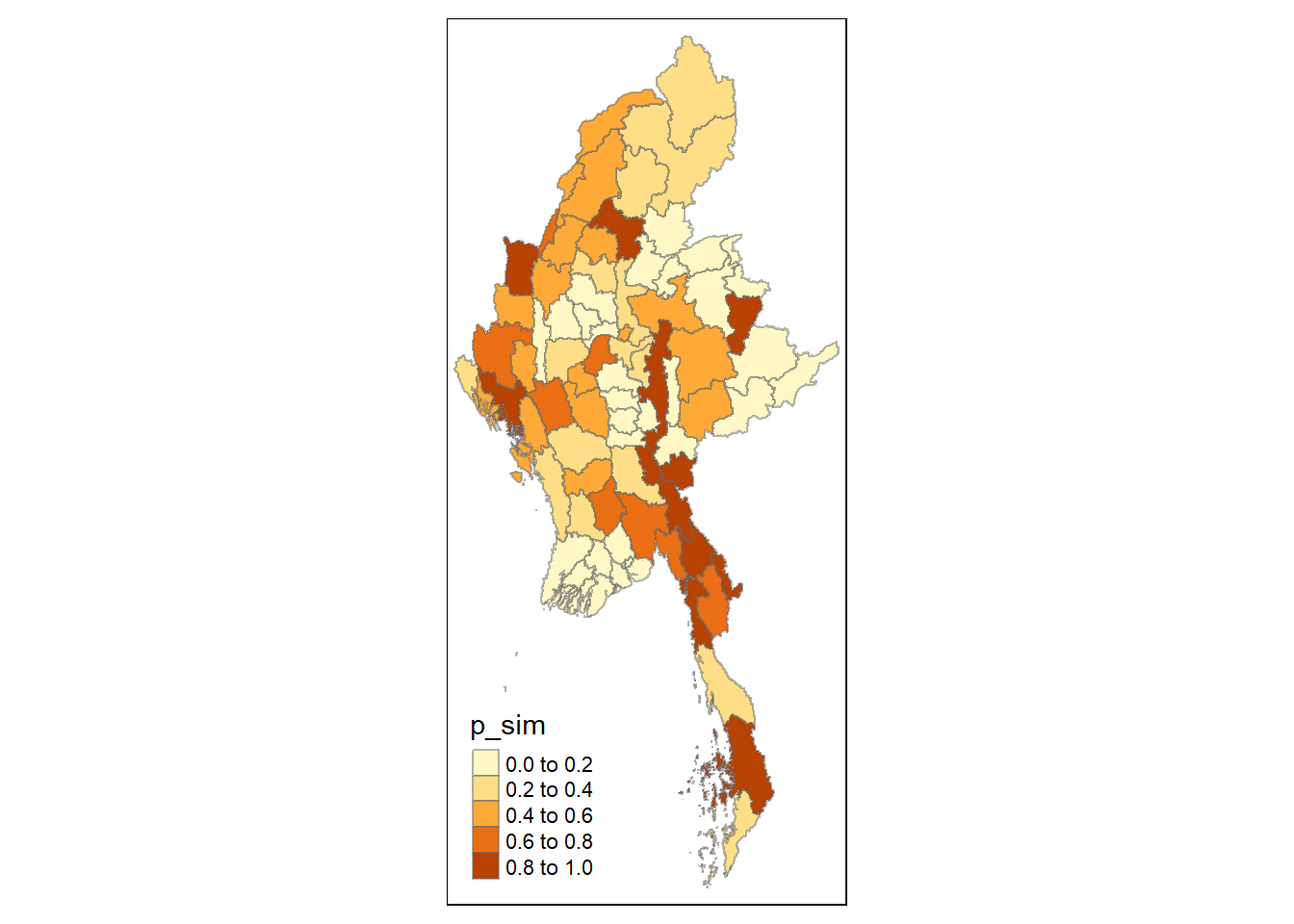
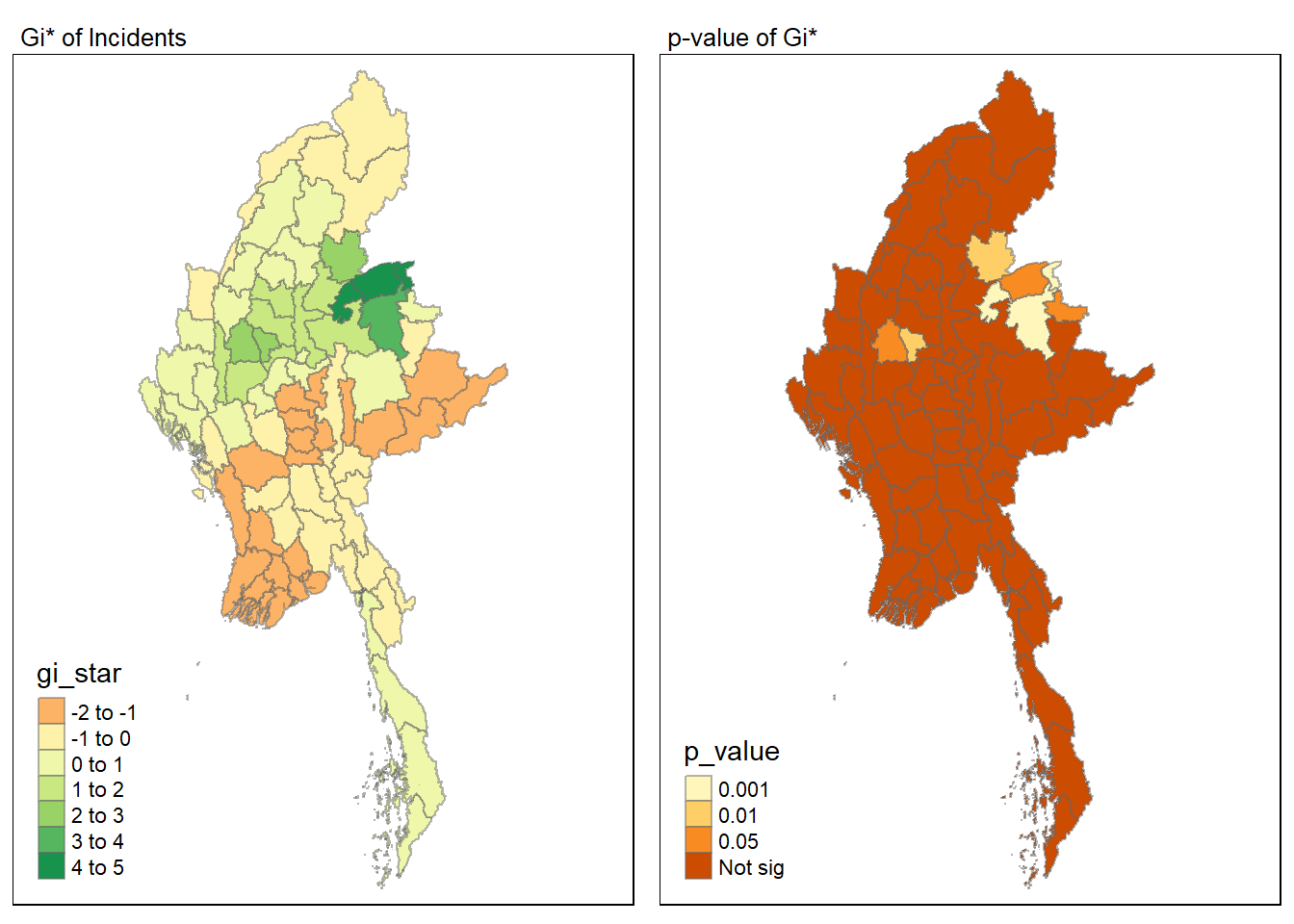
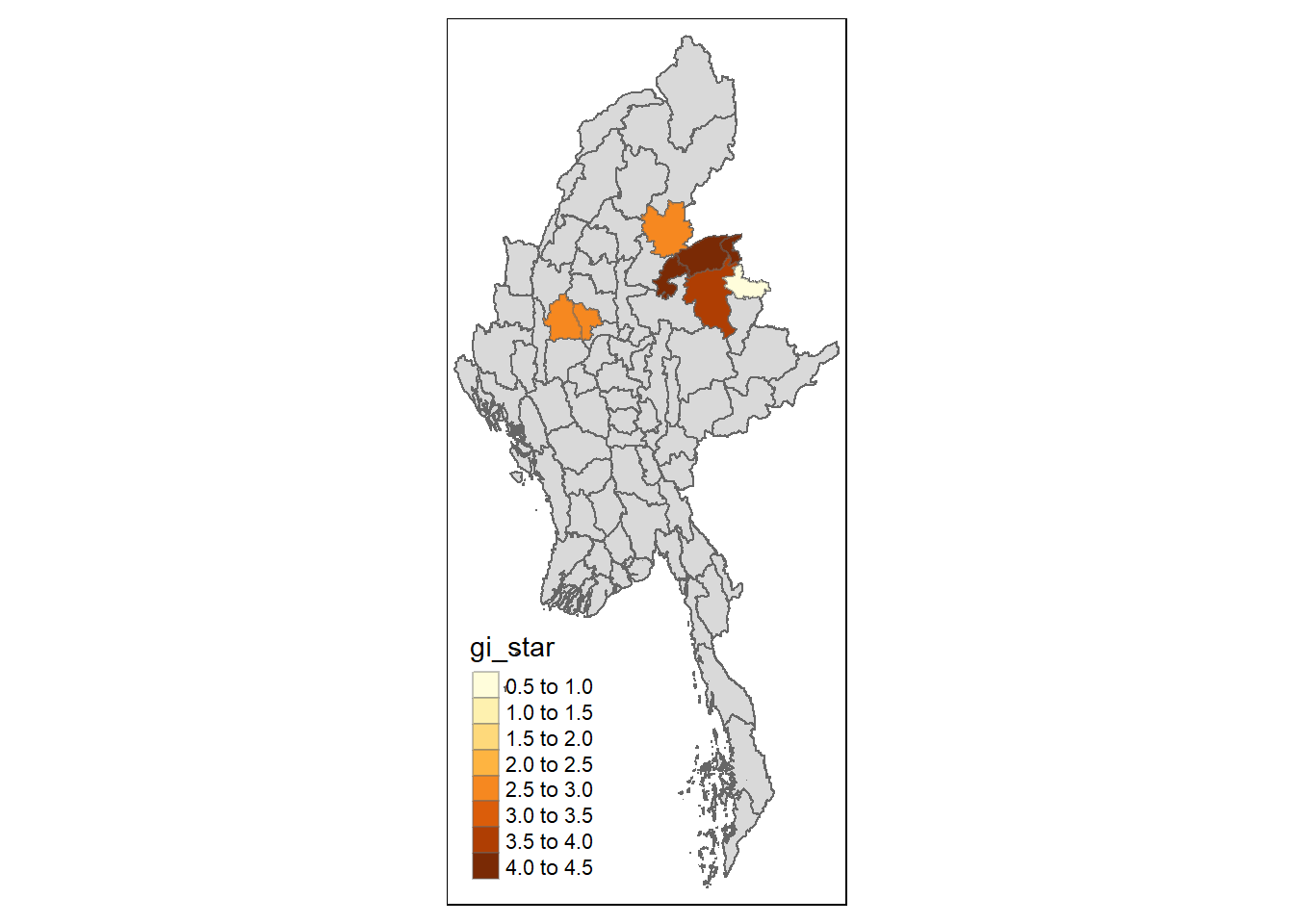
Simple feature collection with 80 features and 8 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 92.1721 ymin: 9.696844 xmax: 101.17 ymax: 28.54554
Geodetic CRS: WGS 84
First 10 features:
nb
1 3, 5, 9, 10, 34, 78
2 4, 6
3 1, 4, 5, 6, 78, 79
4 2, 3, 5, 6
5 1, 3, 4, 34
6 2, 3, 4, 79
7 8, 10, 22, 72, 78, 79
8 7, 9, 10, 21, 22, 29, 73
9 1, 8, 10, 29, 34
10 1, 7, 8, 9, 78
wt
1 0.1666667, 0.1666667, 0.1666667, 0.1666667, 0.1666667, 0.1666667
2 0.5, 0.5
3 0.1666667, 0.1666667, 0.1666667, 0.1666667, 0.1666667, 0.1666667
4 0.25, 0.25, 0.25, 0.25
5 0.25, 0.25, 0.25, 0.25
6 0.25, 0.25, 0.25, 0.25
7 0.1666667, 0.1666667, 0.1666667, 0.1666667, 0.1666667, 0.1666667
8 0.1428571, 0.1428571, 0.1428571, 0.1428571, 0.1428571, 0.1428571, 0.1428571
9 0.2, 0.2, 0.2, 0.2, 0.2
10 0.2, 0.2, 0.2, 0.2, 0.2
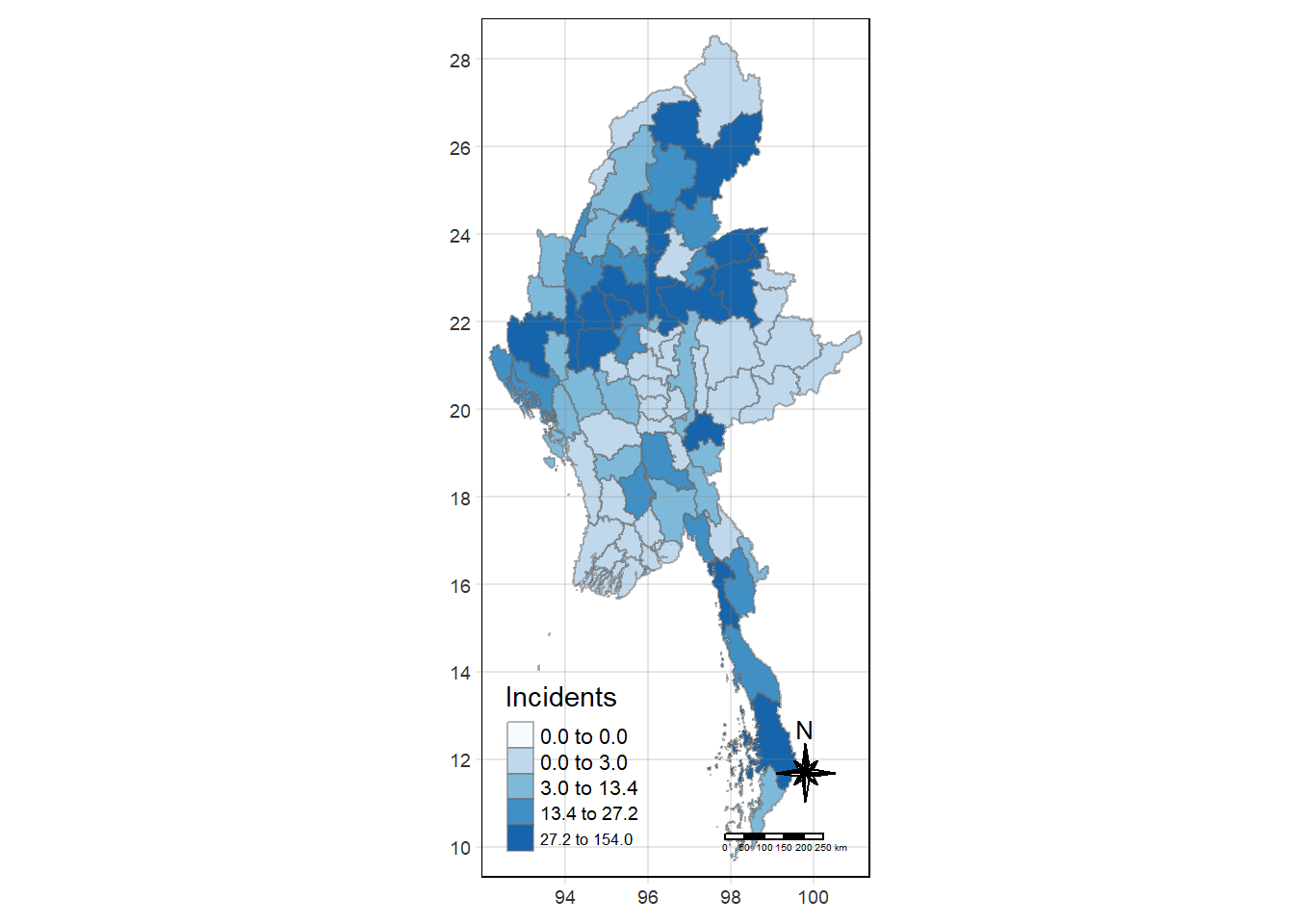
DT quarter event_type year Incidents Fatalities
1 Hinthada 2023Q4 Battles 2023 2 2
2 Labutta 2023Q4 Battles 2023 0 0
3 Maubin 2023Q4 Battles 2023 0 0
4 Myaungmya 2023Q4 Battles 2023 0 0
5 Pathein 2023Q4 Battles 2023 0 0
6 Pyapon 2023Q4 Battles 2023 0 0
7 Bago 2023Q4 Battles 2023 13 50
8 Taungoo 2023Q4 Battles 2023 27 223
9 Pyay 2023Q4 Battles 2023 11 27
10 Thayarwady 2023Q4 Battles 2023 19 25
geometry
1 MULTIPOLYGON (((95.12637 18...
2 MULTIPOLYGON (((95.04462 15...
3 MULTIPOLYGON (((95.38231 17...
4 MULTIPOLYGON (((94.6942 16....
5 MULTIPOLYGON (((94.27572 15...
6 MULTIPOLYGON (((95.20798 15...
7 MULTIPOLYGON (((95.90674 18...
8 MULTIPOLYGON (((96.17964 19...
9 MULTIPOLYGON (((95.70458 19...
10 MULTIPOLYGON (((95.85173 18...